I asked the agent to add a new validation rule. The architecture was clean. The skill was loaded. The agent followed the protocol perfectly: domain first, tests second, adapters last.
And it built the wrong thing.
Not catastrophically wrong. The code compiled, tests passed, and the diff was tidy. But the rule it implemented was not the rule I meant. I had assumed “validate input” meant rejecting empty fields. The agent assumed it meant enforcing format constraints. Both interpretations were plausible. Neither of us had checked.
That moment clarified something I had been circling for weeks: structure and behavior are necessary, but they are not sufficient. The third layer is clarity of intent.
Where this fits in the series
In the first article, I argued that an agent-friendly codebase reduces ambiguity about where changes belong. Hexagonal architecture, golden commands, fast feedback loops — all of that constrains the search space so agents can navigate a repository without guessing.
In the second, I explored how Claude Code Skills encode how changes unfold. Execution protocols, validation gates, layered diff summaries — skills turn engineering discipline into repeatable behavior.
This article addresses the gap that remains even when both layers are in place: what exactly should be built.
| Layer | Question it answers | Mechanism |
|---|---|---|
| Structure | Where does the change belong? | Architecture, boundaries, golden commands |
| Behavior | How should the change unfold? | Skills, execution protocols, validation |
| Intent | What exactly should be built? | Plan Mode, interactive questioning |
Structure constrains location. Behavior constrains process. But neither constrains meaning. And meaning is where the most expensive mistakes hide.
What Plan Mode actually is
Claude Code introduced Plan Mode to separate intention from execution.
Instead of editing files immediately, the agent analyzes the repository and proposes a structured plan before touching the codebase. You toggle it with a simple keystroke, and the entire interaction model changes.
This mirrors something experienced engineers do instinctively: they refine the ticket before writing the code. They ask “what did you actually mean?” before opening an editor. They push back on ambiguous acceptance criteria.
Plan Mode gives agents that same pause.
In practice, when I activate Plan Mode on a feature request, the agent reads the repository structure, identifies relevant files, and proposes a sequence of changes — without making any of them. I can review the plan, adjust it, or reject it entirely before a single line changes.
The shift is not just safety. It is alignment.
A plan is a hypothesis about what the change should be. Reviewing a plan is cheaper than reviewing a diff, and rejecting a plan costs nothing.
The Interactive Question Tool
In version 2.0.22, Claude Code shipped two related capabilities: an interactive question tool and more frequent questioning in Plan Mode. The changelog entry is deceptively brief for something that changes the interaction model this much.
The real shift came when Claude Code added the ability for the agent to ask clarifying questions before finalizing a plan.
This is not a minor convenience. It changes the interaction model fundamentally.
Instead of the agent guessing at ambiguous requirements, it pauses and asks. Scope boundaries, edge cases, compatibility constraints, precedence rules — the kinds of things that experienced engineers surface in design reviews, the agent can now surface before writing code.
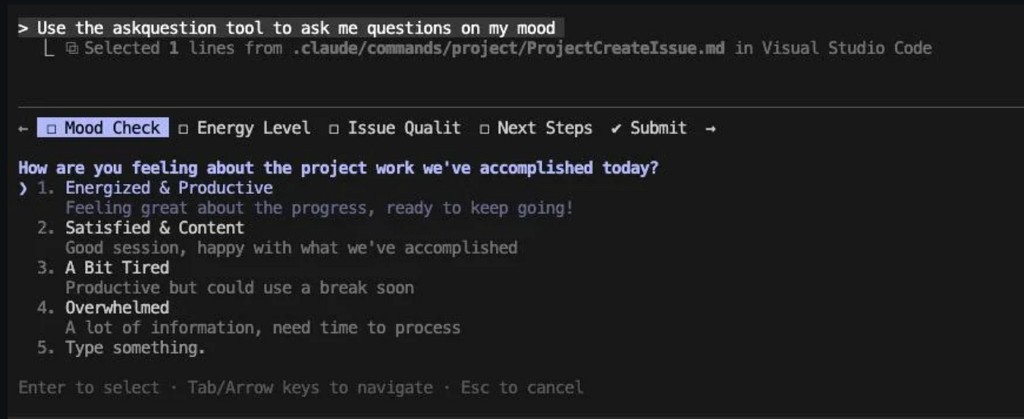
The questions are not generic. They are contextual. The agent reads the codebase, identifies potential ambiguities in the request, and asks targeted questions about the specific decisions it needs to make.
Here is what a typical interaction looks like when I ask the agent to “add input validation to the registration flow”:
| What the agent asks | What it reveals |
|---|---|
| “Should validation reject empty fields, enforce format, or both?” | Scope ambiguity |
| “Should validation errors block submission or show inline warnings?” | UX assumption |
| “Are there existing validation patterns in the codebase I should follow?” | Consistency constraint |
| “Should this apply to API requests, form submissions, or both?” | Boundary definition |
Every one of those questions represents an assumption I would have made implicitly. And every implicit assumption is a potential rework cycle.
Specification boundaries: where the real cost hides
Feature requests carry invisible baggage. Every time someone writes “add feature X,” there are implicit assumptions about behavior, ownership, edge cases, and constraints that never make it into the description.
Without clarification, the agent fills those gaps with plausible defaults. Plausible defaults are dangerous precisely because they look reasonable. The code compiles. Tests pass. The diff is clean. And then someone reviews it and says, “That is not what I meant.”
I started tracking these misalignments. The pattern was consistent:
| Category | Example assumption | Cost of getting it wrong |
|---|---|---|
| Scope | “All users” vs. “only premium users” | Feature flag rework |
| Error handling | Silent failure vs. explicit error | Production incident |
| Data ownership | Who writes vs. who reads | Migration pain |
| Compatibility | Breaking change vs. backward compatible | Rollback pressure |
These are not edge cases. They are the core of what makes a specification complete. And they are exactly the kind of thing that interactive questioning surfaces before code exists.
This is not about making the agent smarter. It is about making the specification explicit.
From linear to dialog-based planning
Earlier AI workflows were linear: input a prompt, receive output, correct what is wrong, repeat. The correction loop was the primary quality mechanism.
Interactive planning introduces dialogue before execution.
| Linear workflow | Dialog-based workflow |
|---|---|
| Prompt -> Code -> Review -> Correct | Prompt -> Questions -> Refined Plan -> Code -> Review |
| Ambiguity surfaces during review | Ambiguity surfaces during planning |
| Correction is the quality mechanism | Clarification is the quality mechanism |
| Expensive: changes already exist | Inexpensive: no code written yet |
The difference is when ambiguity gets resolved. In a linear workflow, you discover misalignment after the agent has already produced a diff. In a dialog-based workflow, you discover it before any files change.
In practice, I now default to Plan Mode for any task that touches more than one architectural layer. The overhead is minimal — a few seconds of reading and answering questions. The savings are substantial: fewer rejected diffs, fewer “that is not what I meant” cycles, and less context-switching between reviewing code and re-explaining intent.
Why this matters now
As agents gain the ability to modify larger systems — spanning multiple files, multiple services, multiple concerns — the cost of specification ambiguity grows non-linearly. A wrong assumption in a single-file change costs you one review cycle. A wrong assumption in a cross-cutting change costs you an afternoon.
Correction after implementation is expensive. Clarification before implementation is cheap.
Interactive questioning introduces productive friction at the right moment — before code exists, when changing direction costs nothing.
This is the same insight that drives test-driven development, design reviews, and architecture decision records. The earlier you surface a mismatch between intention and execution, the cheaper it is to fix. Interactive planning applies that principle to human-agent collaboration.
Putting it together
When I look at how my workflow has evolved across this series, the pattern is clear:
Repository Structure → Execution Skills → Specification Clarity
(where) (how) (what)
Each layer reduces a different class of errors:
- Structure prevents the agent from placing logic in the wrong location.
- Skills prevent the agent from following the wrong process.
- Plan Mode + Questions prevent the agent from building the wrong thing.
None of these layers is sufficient alone. A perfectly structured repo with great skills still produces wrong output if the specification is ambiguous. An agent that asks great questions but operates in a chaotic codebase still produces messy diffs.
The layers compose. And when they align, the interaction shifts from reactive correction to proactive collaboration.
Closing reflection
A one-way prompt assumes completeness. It says: “I have told you everything you need to know.” That assumption is almost always wrong.
A two-way plan assumes imperfection. It says: “Let us figure out what I actually mean before you start building.”
When agents participate in clarifying intent, collaboration becomes alignment-driven rather than correction-driven. The conversation moves from “fix what you did” to “let us agree on what to do.”
That is not a feature of a tool. That is the beginning of specification-aware engineering — and it changes how I think about every task I hand to an agent.