Most teams still ask a narrow question about AI.
They ask whether it helps engineers code faster.
I think that misses the point.
The more useful question is this: what changes inside a team when the cost of iteration starts to fall?
That is the question I have been sitting with lately. Not as a thought experiment, but as a practical one. Scope kept expanding. Expectations around delivery and quality stayed high. Headcount did not grow at the same pace. We could respond in familiar ways: slow down, accept more friction, or try to justify more capacity. Instead, we started looking more carefully at the way we worked.
This isn’t a story about using AI as a shortcut. It’s a story about redesigning execution so a team can learn faster without dropping its standards.
That distinction matters. It is easy to get distracted by shiny demos and optimistic claims. It is harder, and more useful, to ask where AI actually changes the economics of work.
The real bottleneck is not coding
For a long time, many of us in software have treated implementation speed as the main productivity lever. If code gets written faster, then output increases. At first glance, that sounds reasonable.
But in practice, product work is not a straight line from idea to shipped feature. It is a loop. A team forms a hypothesis, shapes it into something buildable, implements it, validates it, measures the result, and then decides what to do next. That loop is where speed is won or lost.
Hypothesis -> Specification -> Implementation -> Validation -> Measurement -> Decision
The real problem is not how quickly a file changes. The real problem is how expensive it is to move through that loop with confidence.
If the loop is heavy, the team slows down. Not because people are weak. Not because ideas are poor. But because learning is expensive.
This is where the conversation gets more interesting for me. AI did not suddenly make our team wiser. It did not remove uncertainty. It did not remove tradeoffs. What it did was help reduce the effort required in several parts of the loop. And once that starts happening, the effect is larger than “faster coding.”
The real advantage is not better answers. It is cheaper iteration.
Why learning velocity matters more than idea quality
We tend to romanticize ideas. We talk about strategy, vision, creativity, and sharp instincts. Those things matter. But many product teams do not underperform because they lack ideas. They underperform because their ideas are expensive to test.
When testing is slow, everything gets heavier. Debates become longer. Scoping gets more defensive. People become more attached to their proposals. Risk feels larger than it actually is. A single experiment starts carrying too much emotional weight.
When testing becomes cheaper, the emotional posture of the team changes. Small bets become easier to justify. Reversible decisions become more natural. Learning starts to replace arguing.
The contrast looks something like this:
| When iteration is expensive | When iteration is cheaper |
|---|---|
| Teams defend ideas longer | Teams test earlier |
| Bets become larger | Bets become smaller |
| Change feels risky | Change feels manageable |
| Learning takes longer | Learning compounds faster |
This is not about being reckless. It is about reducing the cost of finding out what is true.
And that is why I keep returning to learning velocity. It is not a slogan. It is a practical measure of how fast a team can turn uncertainty into insight.
Where AI actually entered the loop
One of the easiest ways to misuse AI is to isolate it at the coding stage and then declare success. That creates nice screenshots, but it rarely changes how a team operates.
What made a difference for us was embedding AI across multiple stages of the execution lifecycle. Not everywhere blindly, but in the places where repetitive, predictable, or cognitively draining work was slowing us down.

The pattern looked more like this:
Idea formation -> Story shaping -> Task breakdown -> Implementation -> Validation -> Analysis -> Documentation
At the hypothesis stage, AI helped challenge assumptions and widen the solution space. This was useful not because it gave the “right” answer, but because it forced us to look at angles we might otherwise ignore.
Prompt: "Give me 5 alternative ways to reduce friction in this funnel step
without changing pricing or adding a new screen."
A concrete example: feeding our Value Proposition Canvas directly into the model and asking it to suggest the next experiments to run — with reasons, success metrics, and whether each addressed a customer pain or created a gain. It did not replace judgment, but it compressed hours of discussion into a sharp starting point.

At the specification stage, AI helped turn rough ideas into draft user stories, acceptance criteria, and Jira tasks that the team could then refine together.
Prompt: "Break this experiment into frontend, backend, analytics, and QA tasks
with draft acceptance criteria."
Dedicated GPTs shaped around our context — like a User Storyteller trained on our domain — made the first draft of a story fast and structured enough that the team could focus on refining rather than starting from scratch.

At the implementation stage, coding agents helped with scaffolding, refactoring suggestions, and test expansion. The benefit was not that they “took over.” The benefit was that they reduced the amount of blank-page work and some of the repetitive effort around first drafts.
At the validation stage, AI helped surface edge cases and review logic before code review even began.
Prompt: "List likely edge cases for this checkout flow change
and suggest tests that would catch regressions."
At the measurement stage, AI helped draft SQL, structure experiment summaries, and accelerate the first pass of analysis.
Prompt: "Draft a SQL query comparing conversion, drop-off rate, and error rate
before and after this experiment."
And at the documentation stage, it helped us codify what we were learning so that knowledge did not remain trapped in a few heads or a few chats.
It’s not about automation. It’s about augmentation.
That framing keeps me honest. AI can accelerate work, but the team still needs judgment, taste, accountability, and care.
Internal friction was the problem we were not naming
Something became clearer as we pushed for faster experimentation. Customers were not the only ones experiencing friction. We were too.
Some of that friction was easy to miss because it had become normal. Repetitive setup work. Manual validation steps. Slow debugging. Heavy reliance on people who held context we did not yet have. Long waits to inspect what had actually happened. Fragile analysis routines. Constant little taxes on progress.
None of those issues looked dramatic on their own. Together, they slowed the system down.
This was one of the most useful reframes for me:
Customers experience friction in the funnel. Teams experience friction in execution.
Once I started seeing internal friction more clearly, I stopped treating it as background noise. I started treating it like a product problem. Something observable. Something designable. Something worth improving.
That mindset changed the conversation. We were no longer only asking how to improve the product. We were also asking how to improve the machine that improves the product.
A simple rule that made us sharper
Over time, one practical rule became more and more useful:
If a task is repetitive and predictable, it is a candidate for acceleration.
Not every repetitive task should be automated. Not every predictable task is worth optimizing. But the rule helped us notice where time was being spent without much leverage.
Here is how that looked in practice:
| Repetitive activity | AI support in practice |
|---|---|
| Drafting user stories | First-pass structure and acceptance criteria |
| Breaking work into tasks | Initial Jira task decomposition |
| Expanding tests | Extra edge cases and scenario coverage |
| Reviewing likely risks | Blind-spot and regression prompts |
| Drafting analysis queries | SQL starting points for experiment review |
| Writing summaries | Structured experiment recap drafts |
This was not glamorous work. It was something better: useful work.
And useful work, when repeated often enough, changes throughput.
Building tooling while still leading
At a certain point, faster experimentation exposed another problem. Debugging and validation were taking too long. We could design and launch experiments, but verifying that everything was wired correctly — targeting rules, segmentation logic, variant distribution — still carried too much friction.
That left us with a familiar choice. Wait for a bigger platform investment. Ask for more people. Or build something narrower ourselves.
We built.
While still managing the team and supporting the broader flow of work, I started vibe coding an internal UI that sits on top of our experimentation platform. The point was not to create a polished product. The point was to remove a bottleneck that was already costing us speed.
This part matters to me because it sits at the intersection of leadership and making. I do not think management should mean drifting too far from the real shape of the work. Sometimes the highest-leverage thing a leader can do is remove a structural constraint directly.
The tool addressed some of the most repetitive and error-prone parts of running experiments. Starting with the setup itself — making experiment creation guided and consistent rather than something each person figured out on their own.
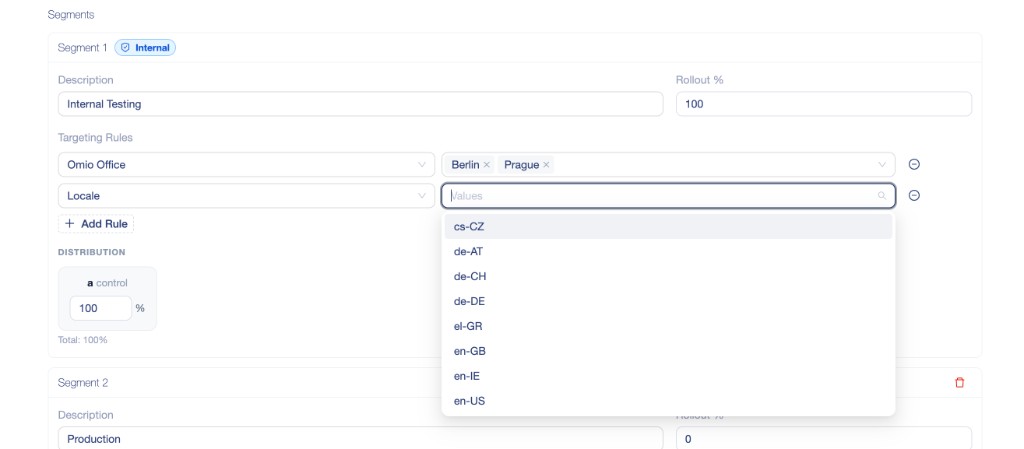
From there, one of the sharpest pain points was targeting and segmentation. Getting those rules right before launch required a lot of back-and-forth and manual checking. The UI made that visual and immediate — you could see the segments, the distribution percentages, and the targeting rules in one place, and fix problems before they became launch-day incidents.
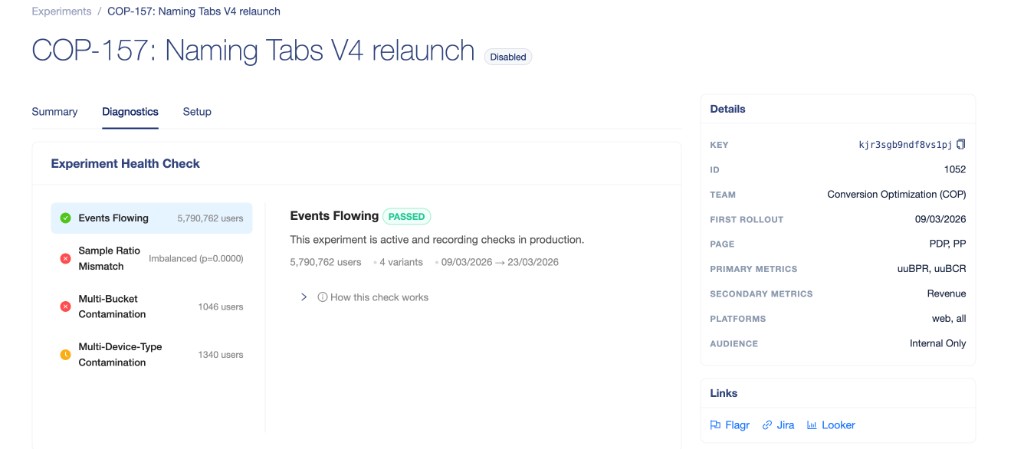
After launch, the next question was always the same: is this experiment actually being tracked correctly? The diagnostics view answered that directly, surfacing health checks — events flowing, sample ratio balance, contamination signals — without anyone needing to write queries or dig through logs.
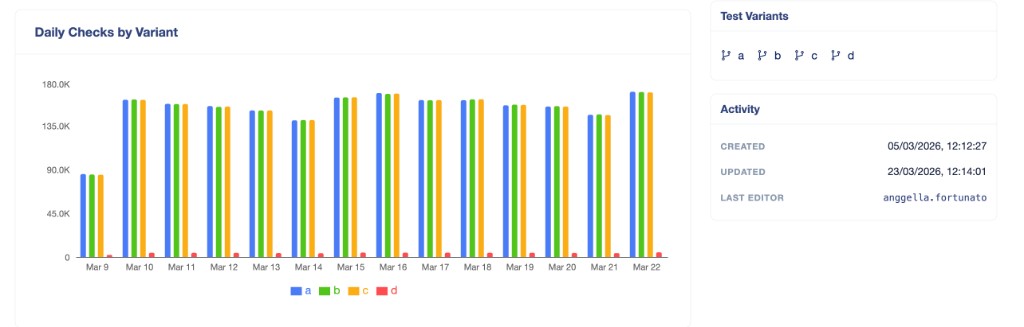
And once an experiment was running, the distribution view let the team confirm quickly that traffic was splitting as expected across variants — something that sounds simple but was previously a manual, error-prone task.
None of those tasks were glamorous. But doing them manually, every single time, was quietly draining the team.
The UI made those checks fast, visual, and consistent. It also became something others could use without needing to know the platform internals, which is how small internal tools earn their place.
I want to be careful here. This is not a story about heroics. It is not “look what one person built at night.” That is not the lesson I care about.
The lesson is simpler.
Lightweight tooling can create structural leverage when it removes recurring friction from a team’s path.
And AI made building that kind of narrow, practical tool more accessible than it would have been otherwise.
What 10x productivity does and does not mean
I am cautious with phrases like “10x productivity” because they are easy to misuse. They can sound like marketing. They can also reduce a complex system into a shallow claim about individuals.
I do not think the interesting version of 10x is about one engineer typing faster than another.
The more honest version is about system-level throughput.
That means asking different questions:
- Are we shipping experiments more frequently?
- Are we validating with more confidence?
- Are we spending less time in avoidable friction?
- Are we learning faster without relaxing our quality bar?
That shift in framing matters because it moves the conversation away from individual mythology and toward system design.
Here is a more grounded way to think about it:
| Individual productivity framing | System throughput framing |
|---|---|
| Faster code generation | Faster hypothesis-to-decision cycle |
| More lines changed | More experiments completed safely |
| Personal speed | Team learning speed |
| Isolated efficiency | Shared leverage |
This isn’t about hero engineers; it’s about building a system that lets ordinary engineering work move with less drag.
In our case, the meaningful gains were not magical. They showed up in shorter loops, faster validation, better visibility, and more reusable structure around the work.
What did not change
This part is important because it protects the whole argument from becoming naive.
We did not stop reviewing code carefully. We did not remove CI checks. We did not loosen quality expectations. We did not outsource ownership to a model. We did not pretend generated output was trustworthy by default.
Those guardrails still mattered. If anything, they mattered more.
| What stayed the same | Why it still mattered |
|---|---|
| Git workflows | Shared discipline and traceability |
| CI/CD checks | Reliable safety net |
| Code review rigor | Human judgment on critical changes |
| Team accountability | Ownership remained with us |
| Architectural thinking | Speed still needed direction |
AI accelerated execution. It did not reduce responsibility.
That sentence captures the balance I want to keep. Without it, speed becomes fragile.
In practice, the gain was compounding
What started as a few accelerations in isolated tasks began to change the rhythm of the system.
Cheaper iteration created room for more experiments. More experiments generated more insight. More insight increased confidence. That confidence made it easier to place smarter bets. Over time, the team was not just moving faster. It was learning in a more continuous way.
The shape of that compounding looked like this:
AI support
-> cheaper iteration
-> faster experiments
-> more observations
-> better decisions
-> more confidence
-> stronger next bets

I like this framing because it avoids hype. It does not claim AI solved everything. It simply shows how small reductions in friction can accumulate into meaningful operating leverage.
This is also where leadership comes back into the picture. Leaders do not need to ask only whether AI is being used. That is too shallow. A better question is where iteration is still unnecessarily expensive.
That question has led me to others:
- Where are we still paying a manual tax?
- Where is context too concentrated?
- Where do delays come from uncertainty rather than complexity?
- What work are we tolerating simply because it has become familiar?
Those are better design questions.
A broader reflection
I do not think AI automatically creates advantage. Access alone is not enough. Plenty of teams have access to the same tools.
What seems to matter more is whether a team can redesign its habits, workflows, and decision loops around the new economics of work. That is less dramatic than the usual AI story, but more useful.
This isn’t about replacing engineers. It’s about giving teams more ways to remove drag from the learning loop.
And it is not finished. I do not think we have reached some final model here. There is still a lot to learn about when to trust acceleration, when to slow down, and how to avoid turning convenience into laziness. Those are not small questions.
But I do feel clearer on one point now than I did before:
The real benefit of AI in engineering is not that it writes code. It is that it can help reduce the cost of learning.
That is the shift I find worth exploring.
So maybe the question to carry into your own week is not “how can AI help me move faster?” It might be something more specific, and more honest:
Where is iteration still too expensive in the way you and your team work today?