Algumas semanas atrás, um dos meus engenheiros disse algo em um 1:1 que ficou comigo.
“Estou usando AI todo dia. Mas não tenho certeza de que estamos realmente melhorando.”
Ele não estava reclamando. Estava sendo honesto. E tinha razão em questionar, porque o sentimento no time era misto. Algumas pessoas estavam mais rápidas. Outras sentiam que o chão tinha se movido embaixo delas. Tínhamos mais uso de AI do que nunca, mas os sinais de entrega não estavam claramente melhorando.
Essa conversa me forçou a fazer uma pergunta mais difícil: como eu sei de fato se a AI está ajudando meus times — e não apenas nos mantendo ocupados?
Não tinha uma boa resposta no começo. O que eu tinha era uma intuição de que as métricas em que eu já confiava — métricas DORA do Accelerate — poderiam me ajudar a ver o que realmente estava acontecendo. Então voltei a elas. Não como teoria. Como uma forma de parar de adivinhar e começar a observar.
O que eu vi quando parei de assumir
Nos meus times, a AI já tinha mudado como as pessoas trabalhavam. Engenheiros estavam usando agentes para planejamento, debugging, criação de testes, documentação. O fluxo de trabalho tinha mudado. Essa parte não estava em questão.
Mas a mudança era desigual. Algumas pessoas tinham reformulado toda a forma de trabalhar. Outras estavam copiando sugestões e editando até ficarem aceitáveis. Alguns tinham silenciosamente voltado a fazer as coisas manualmente porque o output da AI precisava de correção demais.
Percebi isso não porque alguém reportou, mas porque os números de entrega contavam uma história diferente das conversas. As pessoas diziam que a AI estava ajudando. As métricas estavam estagnadas.
Esse gap entre percepção e realidade é onde eu decidi ir a fundo.
Voltando ao DORA — não como teoria, mas como sinal
Voltei às quatro métricas DORA porque elas respondem a pergunta que eu realmente queria responder: estamos entregando valor rápido, com segurança e de forma sustentável?
| Métrica | O que me mostrou |
|---|---|
| Lead Time | Quanto tempo o trabalho ficava parado entre commit e produção |
| Deployment Frequency | Se estávamos de fato entregando, ou apenas codando |
| Change Failure Rate | Se a velocidade estava custando estabilidade |
| Time to Restore | Quão rápido nos recuperávamos quando algo quebrava |
O ponto não era fazer benchmark contra a indústria. Era observar a tendência nos meus próprios times. Se a AI estava genuinamente melhorando como trabalhávamos, eu deveria ver lead time caindo, frequência de deploy subindo, e taxa de falha não piorando.
DORA não me disse se meu time estava usando AI. Me disse se a AI estava tornando nosso sistema melhor.
Em várias conversas com outros managers, ouvi a mesma frustração: “Meu time está usando AI, mas não consigo dizer se está ajudando.” Esse é exatamente o gap que DORA preenche. Te dá algo observável para apontar em vez de ficar trocando impressões.
Na prática, nosso tracking DORA se parece com isso — cada métrica mapeada a um threshold que o time calibra junto:
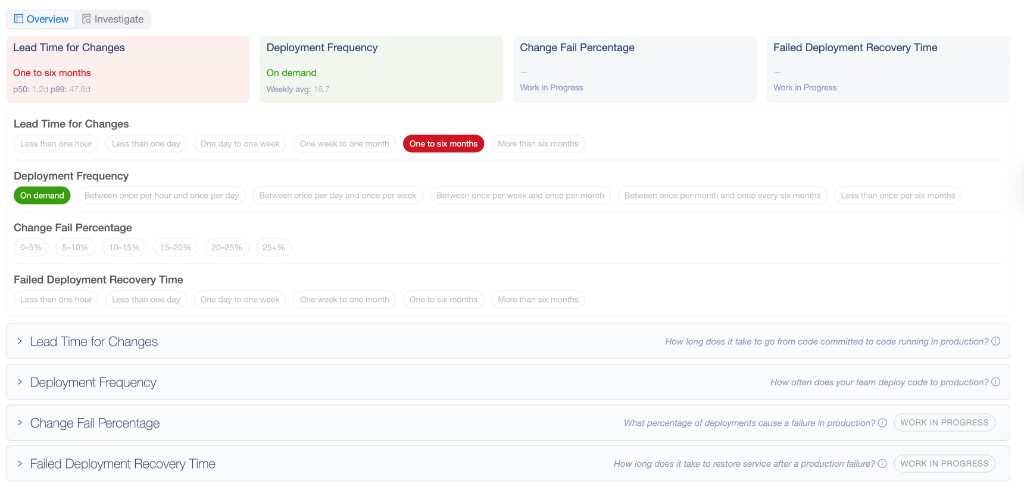
Tornando o invisível visível
A primeira coisa que aprendi é que sem métricas, toda conversa sobre AI vira opinião. “Estou lento.” “AI me ajuda.” “Estamos ocupados.” Isso são sentimentos. Eu precisava de sinais.
Começamos simples. Nada elaborado — apenas visibilidade suficiente para mover a conversa de impressões para padrões.
git log --pretty=format:'%h %ad %s' --date=short > commits.txt
A partir disso, conseguíamos ver lead time por pull request, frequência de deploy por semana e quem estava entregando o quê. A mudança em como as pessoas falavam sobre o trabalho foi quase imediata:
| Antes | Depois |
|---|---|
| “Estou lento” | “Lead time aumentou nesse sprint” |
| “AI ajuda” | “AI reduziu o ciclo médio em 20%” |
| “Estamos ocupados” | “Não estamos entregando” |
Essa mudança importou. Ninguém se sentiu culpado. As pessoas começaram a usar uma linguagem compartilhada sobre o que de fato estava acontecendo, e as retros ficaram mais afiadas porque tínhamos algo concreto para olhar em vez de discutir sobre percepções.
Consolidamos tudo em um dashboard único — velocidade de deploy, status de experimentos, snapshot DORA e padrões de contribuição em um lugar:
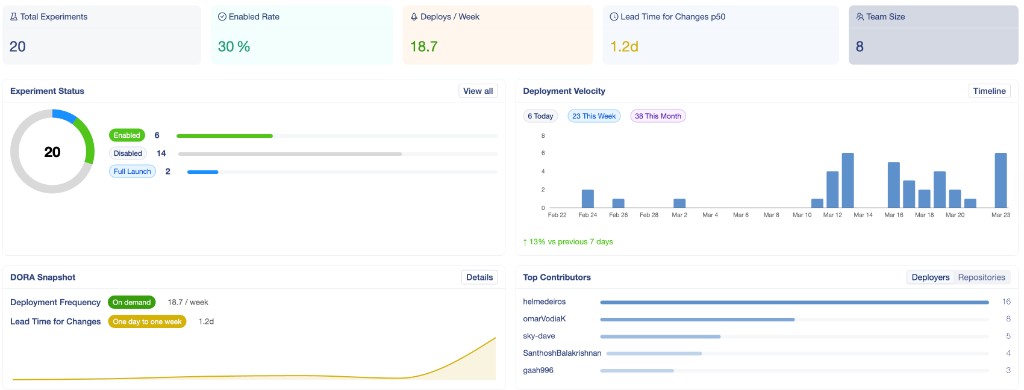
A partir daí, eu podia mergulhar no Lead Time especificamente. O número agregado era útil, mas a tendência contava uma história melhor:
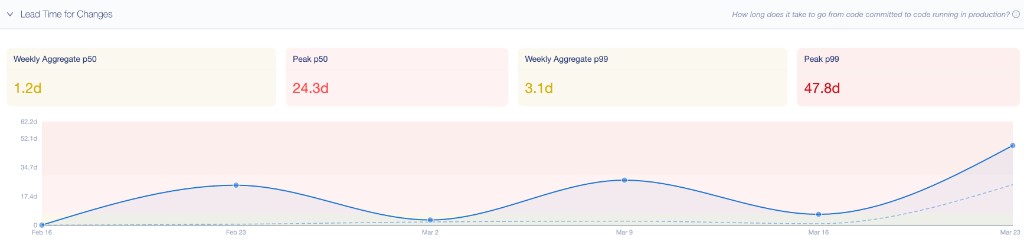
O valor real veio dos dados no nível de PR por baixo. Noventa e cinco PRs mergeados com repositório, lead time e categoria. Quando sentei com um engenheiro e abri essa visão, a conversa de coaching praticamente se conduziu sozinha:
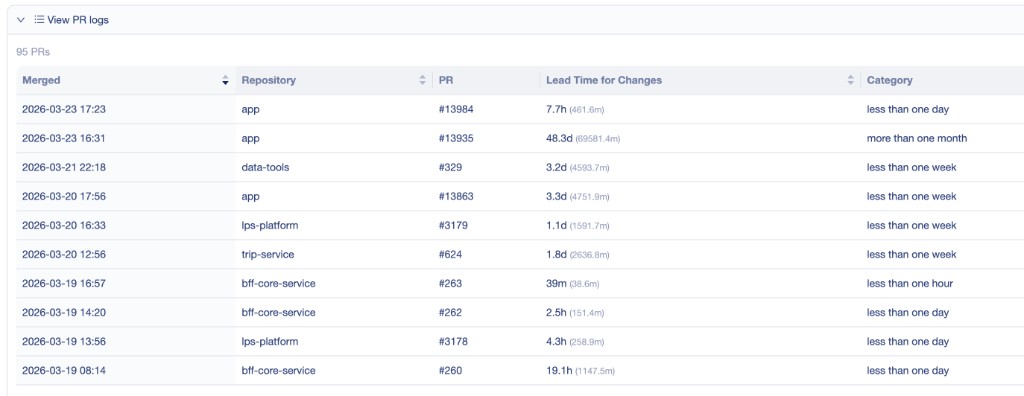
Uma coisa que não esperava: separar o lead time por contexto fez uma diferença grande. Quando alguém estava ausente, os números disparavam — e tratar isso da mesma forma que o fluxo normal seria desonesto:
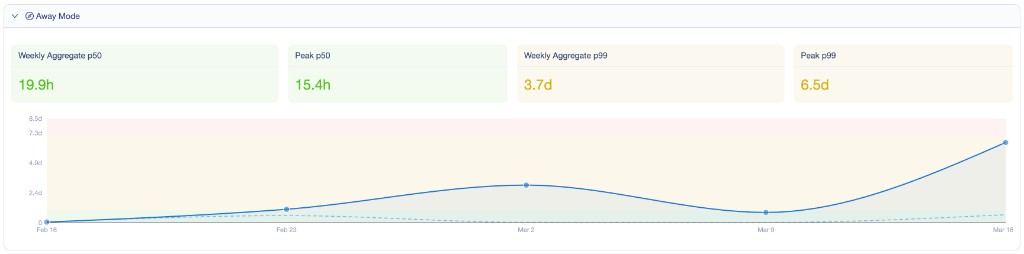
Filtrar por serviços primários nos deu a visão mais limpa de onde o trabalho real de entrega estava:
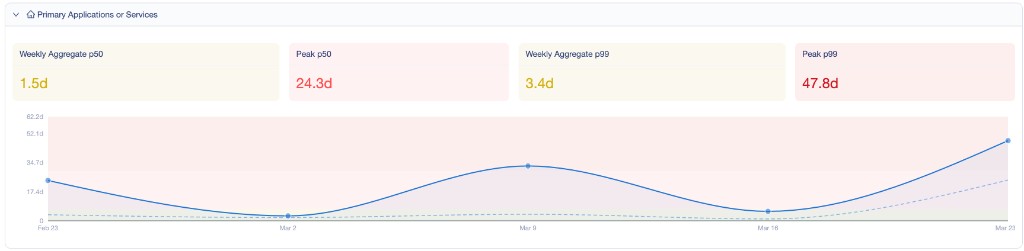
As pessoas estavam em estágios diferentes — e esse era o ponto
Quando eu tinha a visão do sistema, a próxima coisa que precisava era a visão humana.
Nem todos nos meus times estavam no mesmo lugar com AI. Um engenheiro já tinha migrado para fluxos multi-agentes via CLI e estava gerando pull requests em um ritmo que eu nunca tinha visto. Outro ainda era cauteloso, usando sugestões do Copilot mas revisando cada linha como se fosse código de um júnior. Os dois estavam sendo responsáveis. Os dois precisavam de suporte diferente.
Peguei os estágios de adoção de AI do Steve Yegge como forma de falar sobre isso sem que parecesse julgamento:
| Estágio | Como se parece nos meus times |
|---|---|
| 1 | Curioso mas ainda não usando AI no dia a dia |
| 2 | Usando agente na IDE, mas com as guard rails ativas |
| 3 | Confiando mais no agente, aceitando sugestões com menos atrito |
| 4 | AI é o fluxo padrão na IDE |
| 5 | Trabalhando com um agente único via CLI |
| 6 | Rodando fluxos multi-agentes pelo terminal |
| 7 | Gerenciando muitos agentes, mas coordenando manualmente |
| 8 | Construindo orquestradores customizados entre fluxos |
No momento em que comecei a mapear meus engenheiros nesse espectro, a conversa mudou. Parou de ser sobre quem era “bom com AI” e passou a ser sobre onde cada pessoa precisava de suporte para avançar. Um manager com quem converso recentemente adotou o mesmo framing e me disse que foi a primeira vez que o time dele falou sobre adoção de AI sem parecer pressão.
O que acontece quando pessoas pulam etapas
Já vi isso dar errado — em outros times e, honestamente, em momentos iniciais nos meus.
Quando pressionei um dos meus times a começar a parear com fluxos multi-agentes antes de a maioria dos engenheiros ter sequer se acostumado com padrões de agente único, o feedback foi rápido e claro:
- “Está caótico”
- “Não confio no output”
- “Está me deixando mais lento, não mais rápido”
Isso foi culpa minha. Eu tinha pulado etapas porque estava empolgado com o que era possível. O que aprendi é que adoção de AI segue a mesma regra de qualquer mudança significativa: confiança se constrói por pequenas vitórias, não por grandes mandatos. Os engenheiros que avançaram mais rápido foram os que tiveram tempo para experimentar, falhar em pequena escala e construir confiança no próprio ritmo.
O risco real não é adoção lenta. É adoção forçada que queima confiança.
Um manager com quem converso regularmente resumiu bem: “Parei de pedir pro meu time usar mais AI e comecei a perguntar o que ainda estava deixando eles lentos. A conversa sobre AI aconteceu naturalmente depois disso.”
Definindo objetivos que a gente conseguia enxergar
Quando eu tinha os sinais DORA e o mapa de adoção, consegui definir objetivos fundamentados no que era real — não metas aspiracionais tiradas de um deck de estratégia.
Organizei em torno de três coisas que importavam pros meus times:
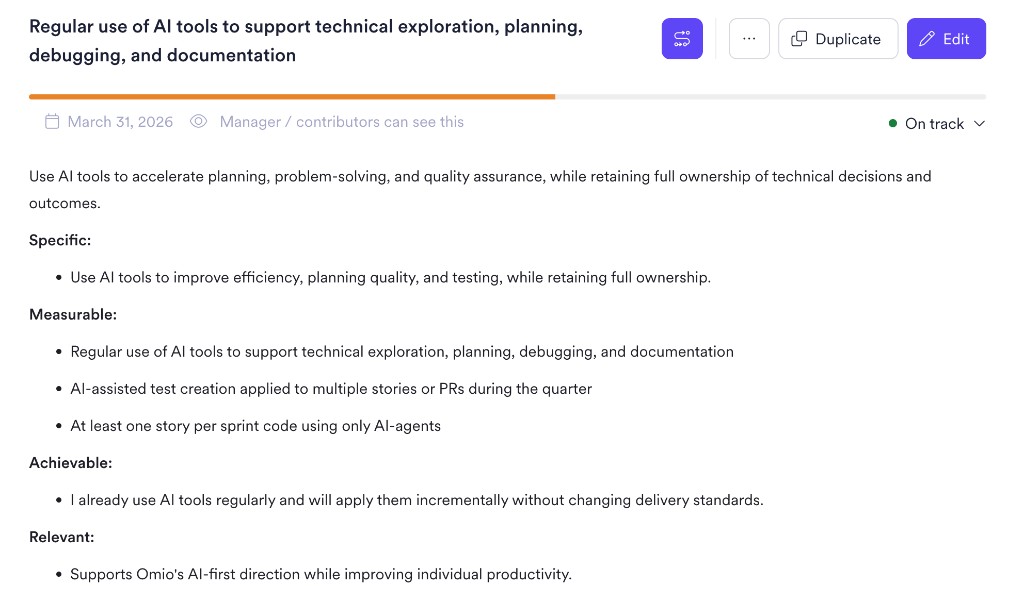
Uso de AI — não mandatos, mas expectativas claras de crescimento:
- Usar AI para planejamento, debugging e documentação como baseline
- Aplicar testes assistidos por AI em pelo menos um fluxo por sprint
- Entregar uma história completa por sprint com envolvimento significativo de agentes AI
Escrevi como objetivos SMART conectando o crescimento de cada pessoa à direção que estávamos seguindo:
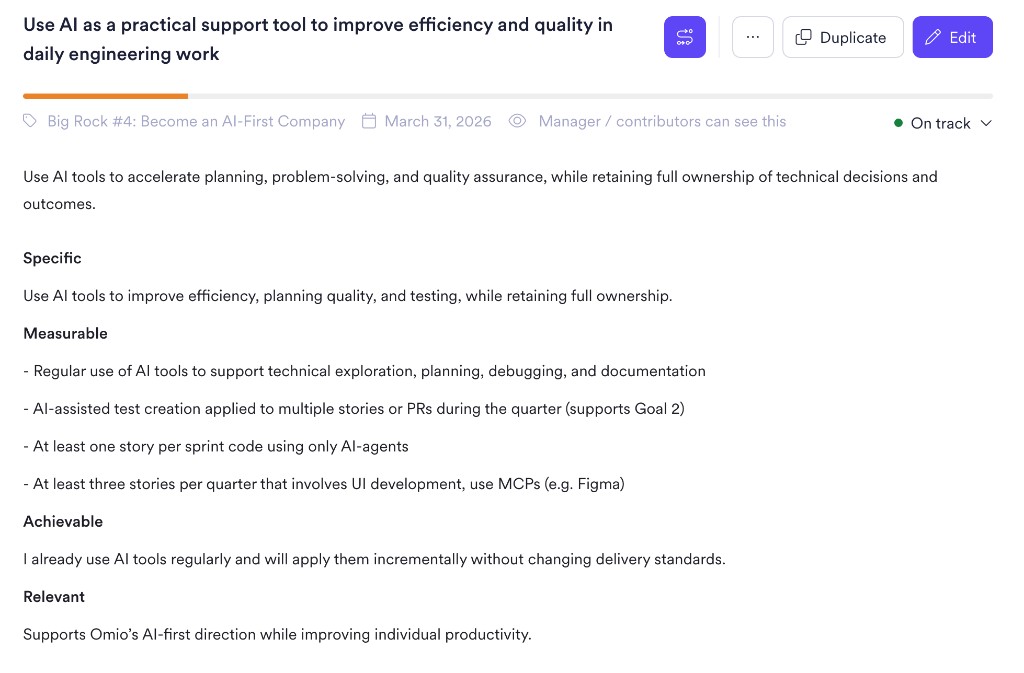
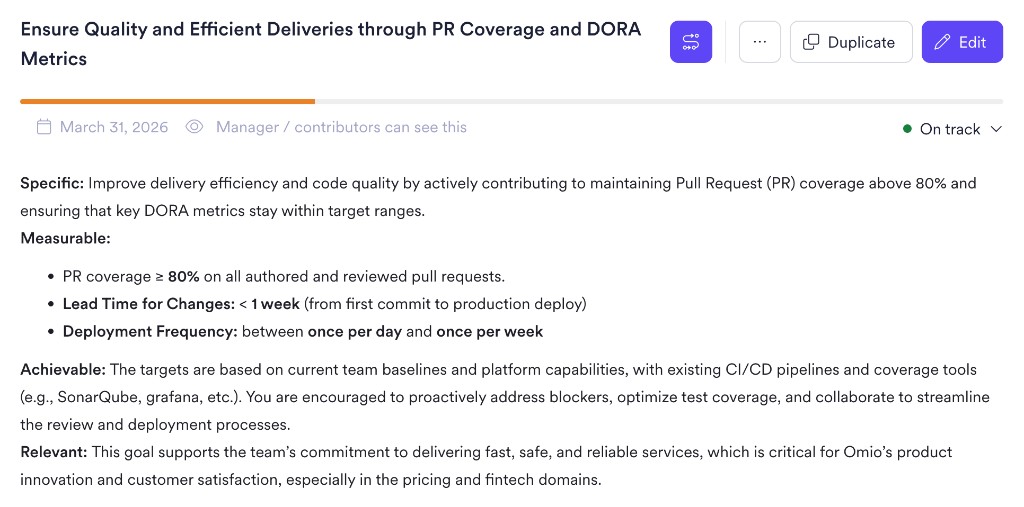
Qualidade de entrega — nos mantendo honestos:
- Cobertura de PR em 80% ou acima
- Lead time abaixo de uma semana
- Frequência de deploy semanal ou melhor
Esses se conectavam diretamente às mesmas métricas DORA que já estávamos rastreando, então não existia gap entre o objetivo e a medição:
Colaboração — garantindo que o aprendizado não ficasse na cabeça de uma pessoa só:
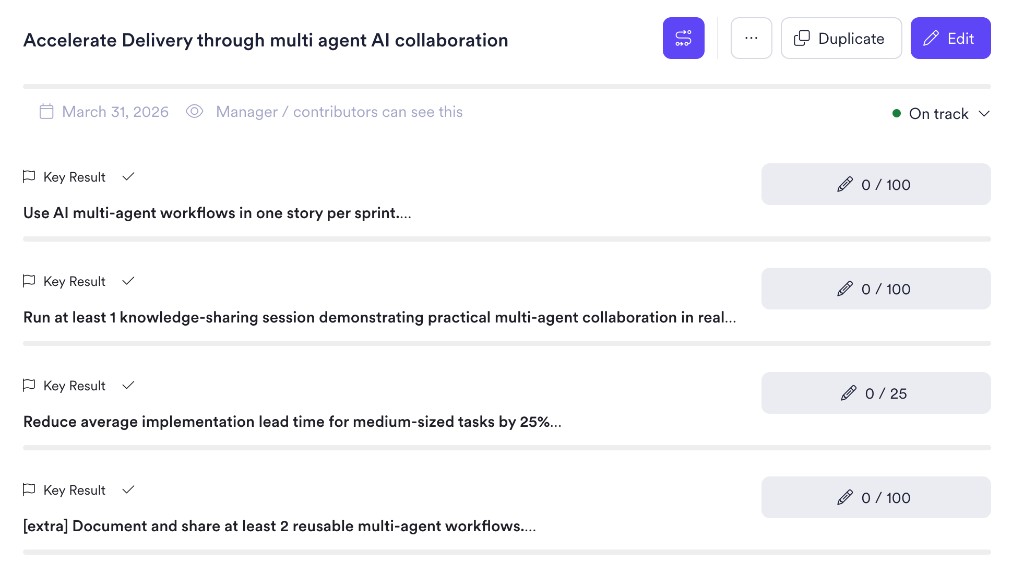
- Usar fluxos multi-agentes em pelo menos uma história por sprint
- Rodar sessões de compartilhamento sobre o que estava funcionando
- Reduzir lead time médio em 25% ao longo do trimestre
Estruturei essa dimensão como um OKR com key results mensuráveis, porque queria que o time fosse dono do resultado junto:
O que fez esses objetivos funcionarem é que cada um deles era observável. Dava para medir progresso, discutir na retro e ajustar sem que a conversa ficasse pessoal.
Desenvolvendo pessoas, não estágios
A tabela abaixo é como penso sobre onde focar quando alguém está pronto para avançar:
| Transição | No que eu foquei |
|---|---|
| Estágio 1 para 2 | Mostrar o que era possível — sessões de pareamento, demos, tarefas de baixo risco |
| Estágio 2 para 3 | Criar segurança — deixar experimentar sem pressão de performance |
| Estágio 3 para 4 | Construir ownership — dar um passo atrás e deixar a AI virar o padrão |
| Estágio 4 para 5 | Expandir escopo — introduzir agentes via CLI para tarefas mais amplas |
| Estágio 5 em diante | Multiplicar impacto — ensinar outros, construir workflows reutilizáveis |
O engenheiro que mencionei no começo — aquele que disse “estou usando AI todo dia mas não sei se estamos melhorando” — estava no estágio 3. Era produtivo mas ainda não confiava no agente o suficiente para deixá-lo liderar. Três semanas depois da nossa conversa, com um objetivo mais claro e o parceiro de pareamento certo, ele migrou pro estágio 5. O lead time dele caiu visivelmente. Mais importante: ele começou a compartilhar o que funcionava com o resto do time.
Isso é o que me importa. Não frameworks. Não percentuais de adoção. Se as pessoas nos meus times estão aprendendo mais rápido e entregando com mais confiança.
O que ainda estou aprendendo
Não tenho isso resolvido. AI está mudando rápido o suficiente para que o que funciona hoje pode não funcionar em seis meses. Alguns dos meus objetivos provavelmente vão precisar ser reescritos. Algumas das minhas suposições sobre estágios vão se provar erradas.
Mas estou mais claro em uma coisa agora do que estava antes. Os times que estão melhorando não são os que estão adotando AI mais rápido. São os que conseguem ver o que está acontecendo, falar sobre isso com honestidade e ajustar sem perder velocidade ou confiança.
DORA me dá a visão do sistema. Os estágios me dão a visão humana. Juntos, substituíram palpite por algo em que eu consigo de fato agir.
Se você está liderando um time por essa mesma transição, a pergunta com que eu começaria não é “como usamos mais AI?” É mais simples e mais honesta: o que está realmente acontecendo no seu time agora — e como você sabe?